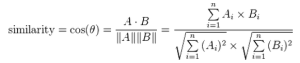IoT is the buzz word these days. Everyone wants to tap into the IoT data streams and build analytic apps. The growth of IoT devices over the next few years is shown below.
IoT apps range from, a baby monitor, telling which lighting conditions or lullaby your baby likes best when sleeping to a predictive maintenance app that monitors array of electric instrumentation for energy demand forecasting and tier pricing.
A device or thing in the IoT world is a piece of hardware such as light or motion sensor that measures a phenomenon such as light intensity, temperature and humidity. These devices need to be connected to the Internet to harness the real power. Commons protocols for data transport are HTTP, MQTT and AMQPS.
Major IoT providers are Microsoft IoT suite, IBM Watson IoT and Amazon IoT. These providers have hub and sdks. Hubs provide infrastructure for brokers to store and forward messages from publishers to subscribers and vice-versa in a secure and scalable fashion. Not all IoT providers support storage (message retention). The incoming messages can be saved to external storage such as HDFS, S3, or Dynamo
SDKs provide APIs for publishing and consuming. Some of the popular ones are Raspberry PI and Arduino device SDKs, here.
Topic/queues are used to publish and receive messages. A topic such as “/grid1/device/reading/area1” can be used to receive readings from electric meters in area1. The messages can be analyzed in real-time or batch mode, the heart of analytics.
Rules can be created using Lambda functions to filter incoming messages and stored in Amazon Dynamo or re-publish to a different topic.
The communication between the devices and the apps can be duplex. This functionality is supported though Shadow API, that lets apps control the devices to take certain actions such as turn a valve off if the temperature exceeds a threshold value.
Special topic like this $aws/things/myElectricMeter/shadow/update are reserved for shadow updates.
A topic can be used as a gateway for hundreds of devices. Each device needs to have its own certificate that can be generated using AWS CLI or AWS SDK.
Esri’s GeoEvent is a product that provides real-time capability to monitor assets such as fleet vehicles and response to events.
Geoevent framework can be leveraged to plugin new data streams though providing a transport and adapter.
Transport encapsulate the semantics of inbound/outbound communication (mqtt, http, amqs.etc) with external hubs such as AWS and Azure IoT hubs. Adapter encapsulates the message format that need to be read and processed in geojson, avro etc. Some of the existing transports, processors and adapters can be found here
AWS transport for geoevent can be found here.
Cmd tools to publish and consume messages from AWS IoT hub are available here(Java and Scala). A GUI app is available here,
In the next post post I will show how to use GE Processsor to leverage Spark streaming and perform machine learning and analytics.